Robots.txt errors are amongst the most common SEO errors you’d typically find in an SEO audit report. In fact, even the most seasoned SEO professionals are susceptible to robots.txt errors. Which is why it’s important to get a deeper understanding of how robots.txt works. By understanding the basics, you’ll be able to create the perfect robots.txt file that makes it easier for search engines to crawl and index your pages. In this guide, we’ll cover:
What is robots.txt Why is robots.txt important How to find your robots.txt file Robots.txt syntax How to create a robots.txt file How to check if your robots.txt is working Robots.txt best practices
By the end of this post, you’ll have an SEO-optimized robots.txt file for your website. Let’s dive right in.
What is Robots.txt?
Robots.txt is a text file created by website owners that instructs search engines on how to crawl pages on your website. Put differently, a robots.txt file tells search engines where it can and can’t go on your site. According to Google: Robots.txt is used primarily to manage crawler traffic to your site, and usually to keep a page off Google, depending on the file type. For instance, if there’s a specific page on your site that you don’t want Google to index, you can use robots.txt to block Googlebot (Google’s web crawler) from crawling that page.
Why is Robots.txt Important?
Contrary to popular belief, having a robots.txt is not essential for all websites. If your website has very few pages, you don’t need to create a robots.txt file for your website. Google has evolved enough to learn what pages to index and what pages to ignore on your site. That said, it’s generally an SEO best practice to have a robots.txt file, even if you have a small website. Why? Because it gives you more control over what pages you’d like web crawlers to index. Let’s take a closer look at the 5 main reasons you’d want to create a robots.txt file for your website:
Block private pages from search engine crawlers: You can use robots.txt to block private pages on your website. Your login page or staging versions of pages on your site should be inaccessible to the general public. This is where you can use robots.txt to prevent other people from landing on these pages. Optimize your crawl budget: Crawl budget is the number of pages Googlebot will crawl on any given day. If you’re having trouble getting all the important pages indexed, you might be facing a crawl budget problem. This is a case where you can use robots.txt to optimize your crawl budget by blocking access to unimportant pages. Prevent crawling of duplicate content: If you have the same content appearing on multiple pages, you can use robots.txt to prevent duplicate pages from ranking in SERPs. This is a common issue faced by eCommerce websites, which can be easily prevented by adding simple directives to your robots.txt file. Prevent resource files from appearing in SERPs: Robots.txt can help you prevent indexing of resource files like PDFs, images, and videos. Prevent server overload: You can use robots.txt to specify a crawl delay to avoid overloading your site with requests.
How to Find Your Robots.txt File
If you already have a robots.txt file, it’s super easy to find it. Just type yoursitename.com/robots.txt in your browser, and if your site has a robots.txt file, it should look something like this:
If your site doesn’t have a robots.txt file, you’ll find an empty page.
Robots.txt Syntax
Before creating a robots.txt file, you need to be familiar with the syntax used in a robots.txt file. Here are the 4 most common components you’ll notice in your robots.txt file:
User-agent: This is the name of the web crawler to which you’re giving crawl instructions. Each search engine has a different user-agent name. Ex: Googlebot is Google’s user-agent name. Disallow: This is the directive used to instruct a user-agent not to crawl a specific URL. Allow: This directive is used to instruct a user-agent to crawl a page, even though its parent page is disallowed. Sitemap: This is the directive used to specify the location of your XML sitemap to search engines.
How to Create a Robots.txt File
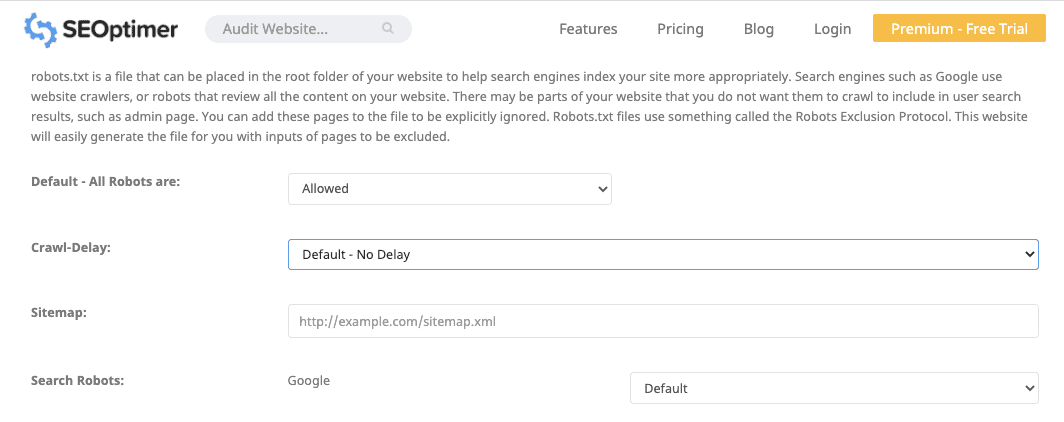
If your site doesn’t have a robots.txt file, it’s easy to create one. You can use any text editor to create a robots.txt file. If you use a Mac, you can create your robots.txt file using the TextEdit app. Open the text document and start typing directives. For example, if you’d like Google to index all your pages and just hide the admin page, create a robots.txt file that looks like this: Once you’re done typing all the directives, save the file as “robots.txt.” You can also use this free robots.txt generator by SEOptimer to generate your robots.txt.
If you’d like to avoid making any syntax errors while creating your robots.txt file, I highly recommend you use a robots.txt generator. Even a small syntax error can deindex your site, so make sure your robots.txt is setup properly. Once your robots.txt file is ready, upload it to the root directory of your website. Use an FTP client like Filezilla to place the text file in the root directory of the domain. For example, the robots.txt file of yoursitename.com should be accessible at yoursitename.com/robots.txt.
How to Check If Your Robots.txt is Working
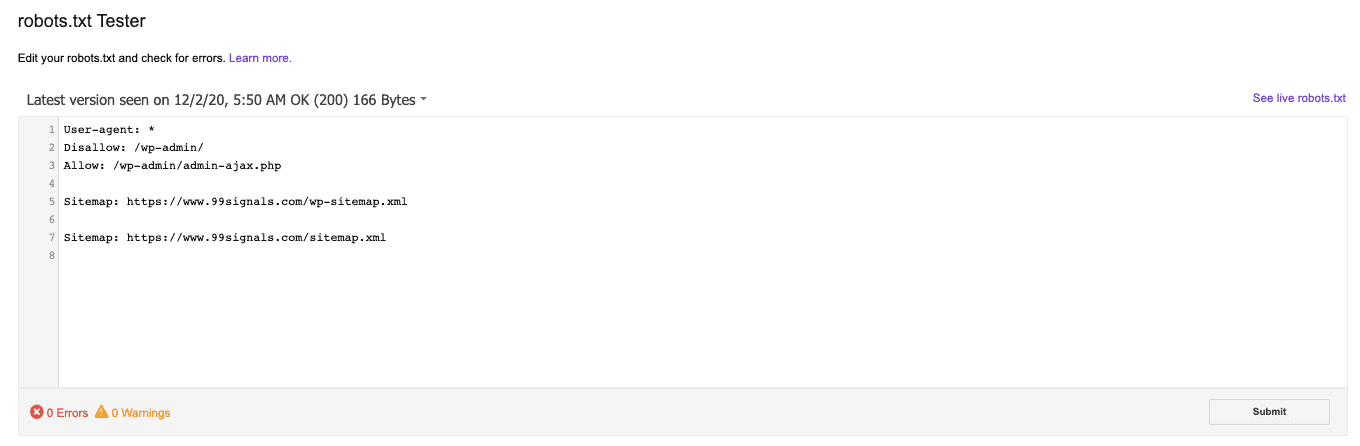
Once you’ve uploaded your robots.txt file to your root directory, you can validate it using robots.txt Tester in Google Search Console. The robots.txt Tester tool will check if your robots.txt is working properly. If you’ve blocked any URLs from crawling in your robots.txt, the Tester tool will verify if the specific URLs are indeed being blocked by web crawlers.
Now, just because your robots.txt is validated once, that doesn’t mean it’ll be error-free forever. Robots.txt errors are quite common. A poorly configured robots.txt file can affect the crawlability of your site. So you need to be on the lookout for issues and make sure your robots.txt file doesn’t contain any errors. The most effective way to check your robots.txt for issues is by using Google Search Console. Login to your Google Search Console account and navigate to the “Coverage” report in the “Index” section. If there are any errors and warnings related to your robots.txt file, you’ll find them in the “Coverage” report. You can also use a tool like SEMrush to audit your robots.txt file for errors. If you have an active SEMrush subscription, run regular site audits on your site to maintain the technical SEO health of your site and to identify and fix robots.txt errors. To check your robots.txt for errors, visit your most recent site audit overview report and look for the “Robots.txt Updates” widget. You’ll see whether SEMrushBot was able to crawl your robots.txt file.
If you’ve made any changes to the robots.txt file, SEMrush will display the number of changes made to it since the last crawl. More importantly, SEMrush will also highlight issues with your robots.txt files and provide recommendations on how to fix them to improve the crawlability and indexability of your website. Side note: SEMrush is a powerful SEO software that can help you with more than just technical SEO analysis. You can use it to perform keyword research, backlink analysis, competitor research, and much more. Try SEMrush Pro for free for 30 days.
Robots.txt Best Practices
Now that you know the basics of robots.txt, let’s take a quick look at some of the best practices you need to follow:
1. Robots.txt is Case Sensitive
The robots.txt file name is case sensitive. So make sure the file is named “robots.txt” (and not robots.TXT, ROBOTS.TXT, Robots.Txt, etc.)
2. Place the Robots.txt File in the Main Directory
Your robots.txt file should be placed in the main directory of your site. If your robots.txt file is placed in a subdirectory, it won’t be found. Bad: yoursitename.com/page/robots.txt Good: yoursitename.com/robots.txt
3. Use Wildcards to Control How Search Engines Crawl Your Website
There are two wildcards you can use in your robots.txt file — the (*) wildcard and the ($) wildcard. The use of these robots.txt wildcards helps you control how search engines crawl your website. Let’s examine each of these wildcards:
(*) Wildcard
You can use the (*) wildcard in your robots.txt file to address all user-agents (search engines). For instance, if you’d like to block all search engine crawlers from crawling your admin page, your robots.txt file should look something like this:
($) Wildcard
The ($) wildcard indicates the end of a URL. For instance, if you’d like to block crawlers from indexing all PDF files on your site, your robots.txt file should look something like this:
4. Use Comments for Future Reference
Comments in your robots.txt file can be helpful to developers and other team members who have access to the file. They can also be used for future reference. To add comments to your robots.txt file, type the hash key (#) and enter your comment. Here’s an example: Web crawlers ignore lines that include a hash.
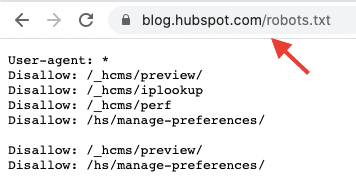
5. Create a Separate Robots.txt File for Each Subdomain
Each subdomain requires its own robots.txt file. As such, if you have a section of your site that’s hosted on a different subdomain, you’ll need to create two separate robots.txt files. For example, HubSpot’s blog is hosted on a subdomain and has its own robots.txt file:
Final Thoughts
Robots.txt may be a simple text file, but it’s a powerful SEO tool. An optimized robots.txt file can improve the indexability of your pages and increase your site’s visibility in search results. For more details on how to create the perfect robots.txt file, you can refer to this robots.txt guide by Google. If you found this article useful, please share it on Twitter using the link below: Editor’s Note: This article was first published on 3 December 2020 and has been updated regularly since then for relevance and comprehensiveness.
How to Create an XML Sitemap for Your Website (and Submit it to Google) Technical SEO Checklist: 10 Technical SEO Tips to Instantly Boost Your Traffic Semrush Site Audit: 10 Most Overlooked Features